
Meta Reuses Disassembled Memory: 3:1 Mix of DDR5/DDR4 Cuts AI Inference Server Needs by Up to 25%
Meta reuses disassembled memory: 3:1 mix of DDR5/DDR4 reduces servers needed for AI inference by up to 25%
2026-06-30 11:32 IT Home
IT Home reported on June 30 that technology media The Register published a blog post yesterday (June 29) stating that Meta has released its self-developed Vistara custom chip solution to reduce the need for purchasing new hardware, allowing new servers to reuse disassembled DDR4 memory.
At the ISCA 2026 conference yesterday, Meta demonstrated the Vistara solution, which expands the memory capacity of new servers and reduces latency by reusing disassembled DDR4 memory.
Meta also published a related paper, pointing out that the expected service life of servers is 3 to 5 years, while memory can continue to be used for 7 to 10 years. In the current global memory crisis, recycling disassembled DDR4 memory can save costs.
Meta will remove DDR4 DIMMs from old servers, install them into new machines that rely on DDR5, and then use its self-developed Compute Express Link (CXL) custom ASIC solution to build a shared memory pool.
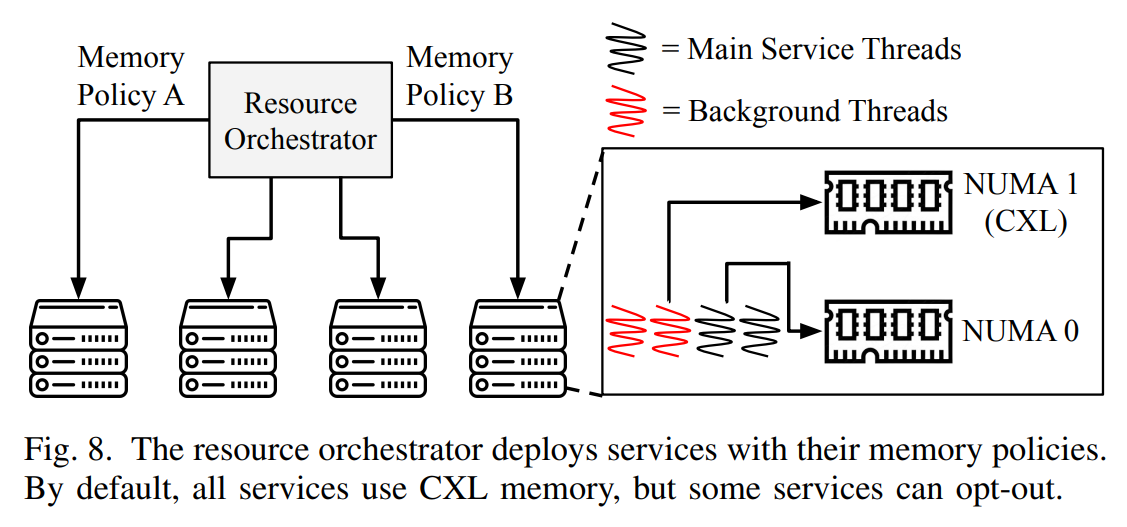
The paper states: "Most CXL solutions bundle DRAM with controllers, making it impossible to reuse DIMM memory, and usually do not support DDR4, which is necessary for reusing old memory. In addition, their high power consumption and high cost further limit their appeal."
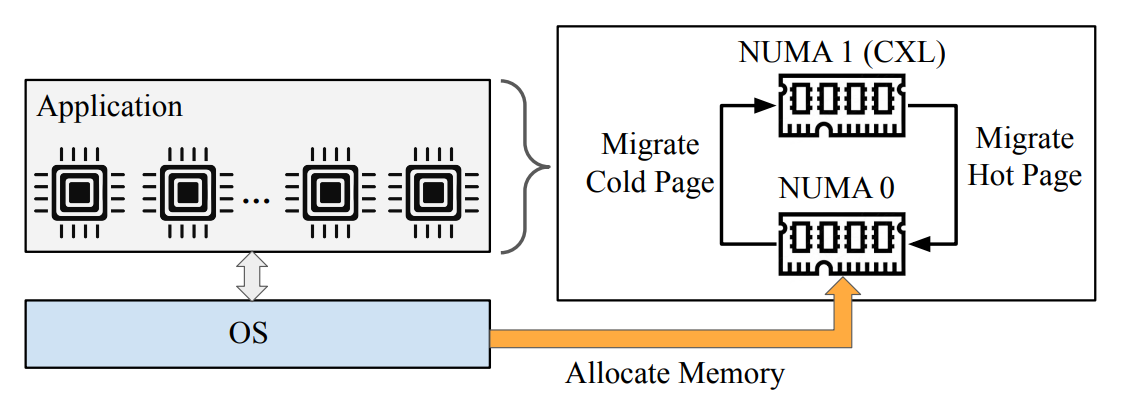
To this end, Meta launched the Vistara ASIC solution, which bridges DDR4 memory to the host processor via a PCIe Gen5 x16 interface compliant with CXL 2.0/1.1 specifications.
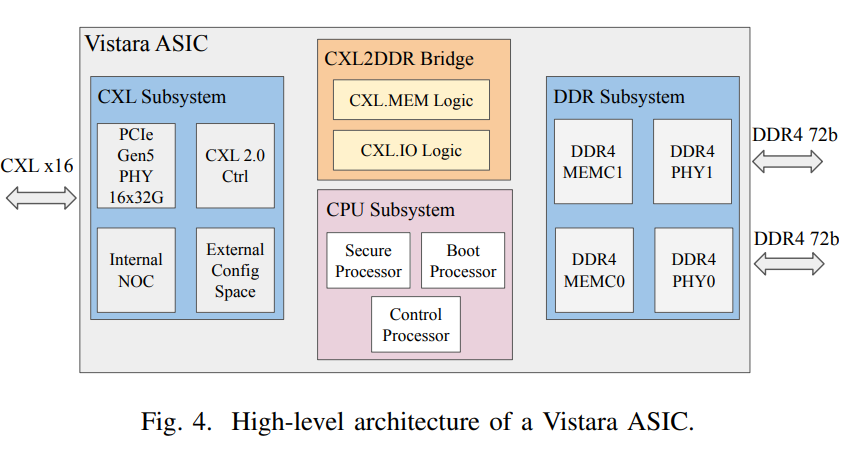
Each Vistara ASIC integrates two independent 72-bit DDR4 memory channels, supporting speeds up to 3200 MT/s, with a maximum capacity of 256 GB per chip (when using 64 GB DIMM memory modules).
Meta deploys this hardware in a device called MemServer. A single MemServer uses one AMD Turin processor with 158 cores and 316 threads.
Each device is equipped with 768GB of DDR5 memory and connects 256 GB of DDR4 memory via the Vistara ASIC. The Vistara CXL card is installed in a dedicated slot at the rear of the chassis, which uses high-volume fans for directed airflow.
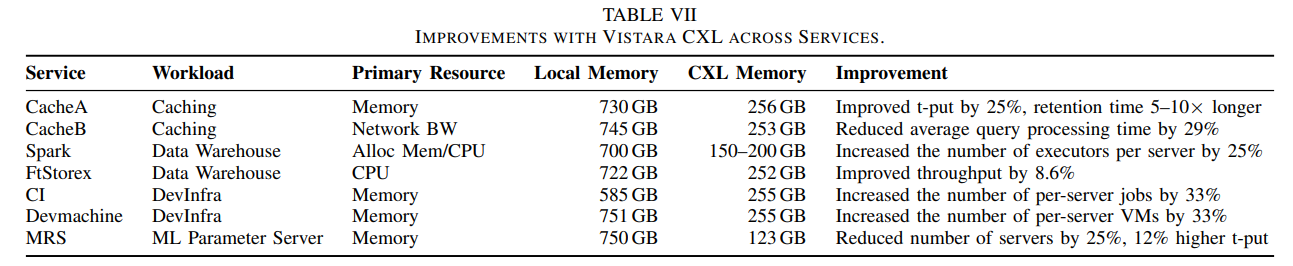
Meta said that Vistara has been put into production in hyperscale infrastructure, covering millions of servers, and is used for disaggregated machine learning inference, big data processing, databases, distributed caching, and CI/CD build systems.
Meta stated that Vistara adopts a hardware-software co-design approach. On the hardware side, a self-developed CXL ASIC is developed; on the software side, an optimization solution is built based on Transparent Page Placement (TPP), and the ratio of local memory to expanded memory is set according to the workload.
The results given in the paper show that this solution can reduce the number of servers for disaggregated machine learning inference by up to 25% and reduce the average latency of distributed caching by 29%.
IT Home attaches the reference paper address.



